Partners involved
Easy Credit is one of the most dynamically developing non-bank financial institutions in Bulgaria, specializing in granting short-term loans with over 19 years of experience. Easy Credit is part of Management Financial Group AD (MFG), a holding company that unites leading companies specializing in the provision of non-bank financial services in Central and Eastern Europe. MFG manages a rich portfolio of successful business models in the field of home lending, personal loans, micro and small business financing, credit cards, digital business and alternative financial products and services. Every day, over 8,000 employees and associates in over 400 offices in Bulgaria, Romania, Poland, North Macedonia and Ukraine take care of serving over 330,000 customers.
Technical/scientific Challenge
We’re addressing how to efficiently process and analyze large, complex, and often unknown datasets in financial services, where traditional serial processing methods are too slow and resource-intensive. This requires transforming data workflows into parallel processes that can scale, handle uneven data distribution, and optimize resource use across distributed systems like Spark and Hadoop. The goal is to ensure fast, reliable, and scalable data analysis while overcoming challenges like data partitioning, processing bottlenecks, and optimizing performance across nodes in a distributed environment.
Solution
To process and analyze large, unknown datasets efficiently, we need a flexible and adaptive approach that leverages parallel processing frameworks like Hadoop and Spark.
Distribution of Data for Parallel Processing & Analysis (DDPP&A) is a strategy, designed to efficiently harness the power of parallel processing frameworks like Hadoop and Spark, making it possible to transform even the most complex data challenges into scalable, adaptive processes.
The process begins with Data Sampling—a method that reads a representative subset of the dataset without loading it completely into the memory. Spark’s sample() method is particularly useful here, as it provides a quick snapshot of the data while conserving resources. Next comes Schema Inference – by using Spark’s inferSchema option, we can easily uncover the hierarchical relationships within the data, identifying key columns and their types without manual intervention. This makes it easier to handle unknown datasets, such as CSV, JSON, or Parquet formats.
Finally, we perform a Statistical Analysis of the data, using basic methods like describe() and summary(). These tools offer an overview of the data, highlighting potential quality issues—like missing values—that could impact downstream tasks. It also informs us about how to partition the data in the most effective way for parallel processing.
The next step is to divide it into manageable chunks—partitions—that can be processed in parallel. This is where Partitioning Based on Data Characteristics comes into play. By leveraging key columns or data ranges, we can ensure that the workload is evenly distributed across multiple nodes, significantly reducing processing time.
Sometimes, data skew is being encountered — an uneven distribution that overloads certain partitions, creating bottlenecks. To mitigate this, we can apply salting techniques or use custom partitioners, which ensure that no single node is overwhelmed by a disproportionate amount of work.
Once the data is partitioned, the challenge is transforming traditionally serial algorithms into parallel versions without changing their outcomes. By rewriting computations using Spark’s RDD or DataFrame APIs—such as map(), reduce(), and filter()—we can process the data across clusters, splitting the workload across multiple nodes.
Additionally, by Identifying Independent Tasks, we isolate computations that don’t rely on other partitions, allowing them to run concurrently. This further maximizes throughput and minimizes processing time.
Another crucial area is Efficient Joins and Shuffles. Spark’s ability to optimize data movements across the network—whether through map-side joins or broadcasting small tables—reduces the overhead of network I/O, accelerating complex join operations that are common in financial datasets.
Finally, Serialization Optimization ensures that data is transferred efficiently between nodes. By configuring Spark to use Kryo serialization, we can minimize the cost of moving data across the cluster, especially during shuffle operations.
The contents of a dataset—specifically the data types such as dates, times, geographical locations, and other domain-specific attributes—play a crucial role in determining effective partitioning strategies for parallel processing. Tailoring partitioning based on data contents can significantly enhance performance by optimizing data locality, reducing shuffle operations, and enabling more efficient query execution.
Dataset Structure-Based Strategies
- Structured Data
Date/Time Partitioning – use case: time-series data such as logs, transactions, or sensor readings.
Strategy: Partition data based on date or time ranges (e.g., daily, monthly, hourly). This facilitates time-based queries and windowing operations, enhancing query performance and enabling efficient data pruning.
Geographical Partitioning – use case: data with geographical attributes (e.g., location-based services, IoT deployments, financial markets, state currencies).
Strategy: Partition data based on geographical regions (e.g., country, state, city). This improves data locality for region-specific analyses and reduces the amount of data scanned for location-based queries.
- Semi-Structured Data
Hierarchical Attribute Partitioning – use case: nested data with hierarchical relationships (e.g., organizational structures, nested categories).
Strategy: Partition data based on hierarchical attributes, allowing for efficient traversal and querying of nested structures.
- Unstructured Data
Content-Based Feature Partitioning – use case: multimedia data or text data requiring feature extraction.
Strategy: After feature extraction (e.g., image features, text embeddings), partition data based on feature similarities or clusters to optimize parallel processing of related content.
Statistical Properties-Based Strategies
- Data Cardinality – number of unique values in key columns.
Date/Time: When dealing with high cardinality date/time fields, we need to ensure partitioning aligns with temporal ranges to support efficient time-based aggregations.
Geographical Data: For high cardinality geographical fields, we need to consider spatial partitioning techniques that group proximate locations together.
- Data Distribution – uniform/non-uniform data distribution
Date/Time: Certain periods (e.g., holidays, weekends; or workdays on financial markets) may have higher data volumes. It would be possible to implement dynamic partitioning or salting within these time ranges to balance the load.
Geographical Data: Some regions – continents, countries, cities; may generate more data than others. In this case, we can apply adaptive partitioning to distribute heavily loaded regions across multiple partitions.
Content-Based Partitioning Strategies
- Temporal Data Partitioning – dates, times, timestamps
Range partitioning – we can divide data into partitions based on temporal ranges (e.g., by year, month, day).
Sliding window partitioning – we can create overlapping partitions using sliding windows to handle continuous data streams.
- Spatial Data Partitioning – geographical coordinates, regions, spatial identifiers
Geohashing – in this case we encode geographical coordinates into geohash strings and partition based on geohash prefixes. This maintains spatial locality, enabling efficient spatial queries and range searches.
Spatial grid partitioning – we can divide the geographical area into a grid of fixed-size cells and assign data to partitions based on cell locations.
- Categorical Data Partitioning – categories, labels, enumerations
Hash partitioning on categories – we can apply hash functions to categorical fields to distribute data evenly across partitions.
Category clustering – we can group related categories into clusters and assign each cluster to a specific partition.
- Hierarchical Data Partitioning – hierarchies, nested structures
Parent-child partitioning – it would be beneficial to partition parent and child records together to optimize hierarchical joins.
Multi-level partitioning – we also can apply hierarchical partitioning based on multiple levels of the hierarchy.
- Event-based data partitioning – event identifiers, sequence numbers
Sequence number partitioning – we partition data based on event sequence numbers to maintain the order of events within partitions.
Event type partitioning – we assign different event types to specific partitions to segregate diverse event streams.
Stock market data is typically well-structured, consisting of tabular formats with predefined schemas. May include hierarchical relationships such as stock exchanges, sectors, industries, and individual stocks. Stock market generates vast amounts of data continuously throughout trading hours. Data points are timestamped, representing the temporal aspect of trading activities. Certain stocks (e.g., high-volume, large-cap stocks) may have disproportionately more data.
Data Content Types:
- Date/Time: Precise timestamps for each trading event.
- Categorical Data: Stock symbols, exchange identifiers, sector classifications.
- Numerical Data: Prices (open, close, high, low), volumes, bid/ask sizes.
- Textual Data: News headlines, analyst reports (if integrated).
Temporal Data Partitioning
- Range Partitioning by Timestamp:
We can define partitions based on predefined time intervals, such as hourly or daily.
Example: Partition data into separate HDFS directories for each day.
- Sliding Window Partitioning:
We can use Spark Structured Streaming window functions to create overlapping time windows.
Example: Create 10-minute sliding windows with 5-minute slide intervals for real-time moving averages.
Categorical Data Partitioning
- Hash Partitioning on Stock Symbols:
Apply a hash function to the stock_symbol column to distribute data evenly across Spark partitions.
df.repartition(num_partitions, col(“stock_symbol”))
- Sector-Based Clustering:
Group stocks by their respective sectors and assign each sector to specific partitions.
Example: Create a mapping of sectors to partitions and distribute data accordingly.
- Hierarchical Data Partitioning
Multi-Level Partitioning:
First partition data by exchange_id, then within each exchange we partition by stock_symbol or timestamp.
Algorithm, applied on the stock market data, loaded in HDFS:
- Initialize Spark session – we start by configuring Spark with necessary settings for optimal performance.
- Define schema we’ve explicitly defined the schema for the stock market data to ensure correct data types.
- Read data – the next step is to load the data from a CSV file into a Spark DataFrame.
- Convert timestamp to date – we extract the date from the timestamp for range partitioning.
- Handle data skewness – we can apply salting to high-volume stock symbols like AAPL and MSFT to distribute data evenly.
- Repartition data – then we apply hash partitioning based on stock_symbol to ensure balanced data distribution.
- Write partitioned data: Save the partitioned DataFrame to Parquet files with partitionBy on date and sector.
Scientific impact
This approach enables financial services to harness the full potential of large-scale data analysis in a faster, more efficient, and scalable manner. By transforming serial processes into parallel workflows and optimizing resource utilization, the solution significantly accelerates insights and decision-making. This improves the ability to detect trends, assess risks, and respond to market changes in real-time. Furthermore, the adaptive techniques for handling data complexity, distribution, and processing bottlenecks can be applied to various scientific fields that rely on big data.
Benefits
The Distribution of Data for Parallel Processing & Analysis (DDPP&A) solution offers a structured, scalable, and efficient way to handle large, unknown datasets in financial services. By incorporating adaptive techniques—from data profiling and partitioning to algorithm transformation and optimization—this approach ensures that even the most complex datasets can be processed quickly and accurately.
Success story # Highlights
- A model for distribution of data for parallel processing and analysis has been developed and implemented as a use case for financial markets data.
- The model is generic and can be applied to a variety of fields as the specific execution depends on automatically examining the data from different point of views.
Figure 1:
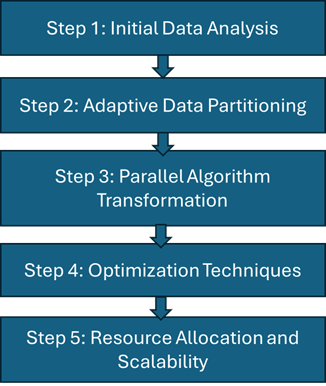
Figure 2: DDPP&A set of algorithms, divided in categories.

Contact:
- Venko Andonov, [email protected], University of National and World Economy, Sofia
- Valentin Kisimov, [email protected], University of National and World Economy, Sofia