Partners involved
Coca-Cola Hellenic, one of the largest bottlers of Coca-Cola products worldwide, serves over 600 million consumers across 28 countries. With a workforce of over 28,000 employees, Coca-Cola Hellenic ensures the production, distribution, and sales of its products across an extensive network of facilities and partners. The company operates over 50 bottling plants and collaborates with thousands of suppliers, making it a crucial player in global supply chains. Each day, Coca-Cola Hellenic processes massive amounts of data from sales, production, logistics, and customer interactions to ensure efficient operations and timely delivery of products to markets. Coca-Cola Hellenic is committed to sustainability and innovation, continuously investing in green technologies, efficient resource use, and the digital transformation of its operations. This commitment to data-driven insights and operational excellence ensures that Coca-Cola Hellenic remains a key player in one of the world’s most competitive industries, delivering quality beverages to millions of consumers.
Technical/scientific Challenge
Coca-Cola Hellenic needed to improve the accuracy, consistency, and reliability of data being processed across its diverse datasets from multiple sources (sales figures, production schedules, logistics data). The company required an advanced data quality management solution capable of handling large-scale data ingestion while minimizing resource usage and ensuring compliance with internal data governance standards.
Key challenges included:
- Ensuring that large, distributed datasets met predefined data quality standards in real-time.
- Managing memory and computational resource efficiency without compromising on data quality.
- Scaling the system to support growing datasets while maintaining high-quality data for decision-making processes.
Solution
The proposed solution consists of developing a comprehensive data quality management environment that leverages PySpark and Amazon Deequ within a High-Performance Data Analytics (HPDA) framework. This approach is designed to be scalable, customizable, and capable of performing automated data quality checks on various datasets, such as those commonly handled by Coca-Cola Hellenic (e.g., sales, production, logistics). The system works by integrating PySpark for distributed data processing and Amazon Deequ for automated data quality checks, ensuring that the solution is both flexible and efficient in managing large datasets.
The solution begins by loading large datasets into the PySpark environment. PySpark enables distributed processing, allowing data to be processed in parallel across multiple nodes, which significantly enhances the speed and efficiency of handling massive datasets. This is particularly useful for companies like Coca-Cola Hellenic that deal with large-scale data from multiple sources. Once the data is processed, Amazon Deequ performs a series of automated data quality checks across the distributed data. These checks ensure that data is reliable and ready for decision-making processes. The key checks include:
- ApproxQuantile: Utilizes HPDA capabilities to efficiently calculate approximate quantiles and identify outliers in the data distribution, crucial for accurate forecasting and decision-making.
- Compliance: Ensures that the data adheres to business rules and regulatory standards (e.g., product codes, dates) within the HPDA environment.
- DataType: Verifies that each column maintains consistent data types (e.g., integers for sales values, strings for product codes) to prevent type mismatches, ensuring structural integrity in the HPDA system.
- Distinctness: Measures the distinctness of values within columns, helping detect redundancies and ensuring that key identifiers (e.g., product IDs) remain unique and accurate in large datasets managed through HPDA.
In addition to the built-in capabilities of Amazon Deequ, custom Python methods are used to extend functionality and provide more specialized checks, fully supported by HPDA, such as:
- MutualInformation: Measures dependencies between variables (e.g., the relationship between sales and logistics data), providing deeper insights into operational performance within the HPDA environment.
- PatternMatch: Verifies that fields (e.g., product codes, dates) conform to specific patterns, ensuring data consistency across records handled in the HPDA system.
- UniqueValueRatio and Uniqueness: Ensures the uniqueness of critical identifiers (e.g., product IDs, transaction codes) by checking the ratio of unique values within each column, critical for large datasets in the HPDA architecture.
Impact
- Automated and scalable data quality checks are proposed to ensure that data used in supply chain analysis and decision-making is both accurate and reliable. This enables the company to make informed decisions with confidence.
- Real-time, high-quality data could help optimize inventory management, production schedules, and transportation routes, which would lead to a significant reduction in operational costs and improved service delivery.
- The solution’s advanced functions are designed to minimize memory usage and optimize computational resources, ensuring that the system remains cost-efficient while still maintaining high data quality standards.
- With its flexibility, the solution is expected to handle expanding data needs and scale alongside growing operations, ensuring that data quality is not compromised as the system scales up.
- The system’s ability to reduce resource consumption and optimize data processing will directly contribute to lowering operational expenses while maintaining high performance in data-intensive environments.
Benefits
- The proposed integration of Amazon Deequ and custom Python methods provides Coca-Cola Hellenic Bulgaria with a powerful tool for ensuring the accuracy and reliability of their data.
- By automating the process of checking and correcting data quality issues in real-time, this approach would reduce manual effort and speed up decision-making.
- The solution is designed to scale with the company’s growing data needs, ensuring that it remains cost-efficient as the data volume increases.
- The proposed solution optimizes memory usage and computational resources, potentially leading to significant cost savings while maintaining high data quality.
Success story # Highlights
- Improving data quality in large-scale distributed environments has become more accessible through the proposed integration of Amazon Deequ and custom Python methods.
- The solution is scalable and flexible, designed to accommodate the company’s growing data needs while maintaining high data quality standards.
- The proposed solution can be implemented across various infrastructure setups, ensuring compatibility and easy deployment in both existing and evolving systems.
Figure 1. Data quality management workflow
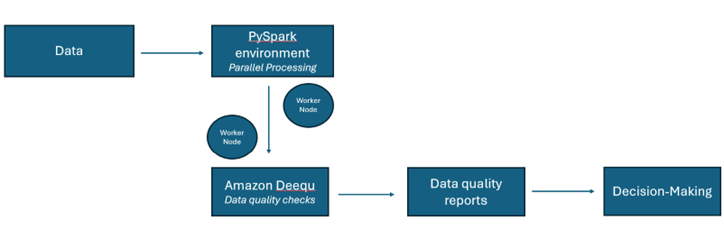
Figure 2. Mutual Information heatmap. The heatmap shows the mutual information scores between different variables. Mutual information measures the dependency between variables (i.e., how much knowing one variable tells you about another). Darker squares indicate higher dependency, meaning certain variables are more closely related (e.g., Product Codes and Sales Values might have higher mutual information, implying a strong relationship between the two). Lighter squares represent lower mutual information, meaning the variables are less related.
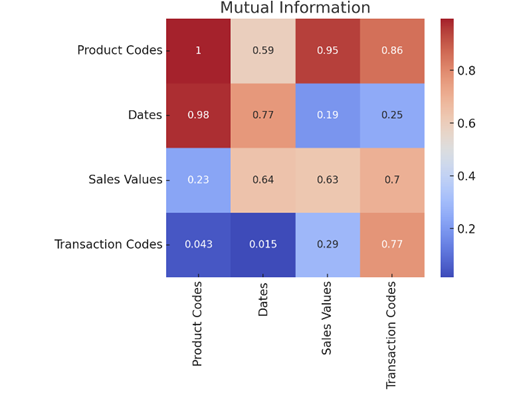
Figure 3. Pattern match. 85% Match: The majority of the data conforms to the expected patterns (e.g., product codes, transaction codes following a specific format). 15% No Match: A small portion of the data does not follow the expected patterns, indicating potential data quality issues (e.g., incorrect formatting or data entry errors).
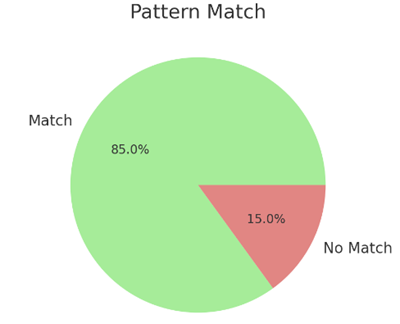
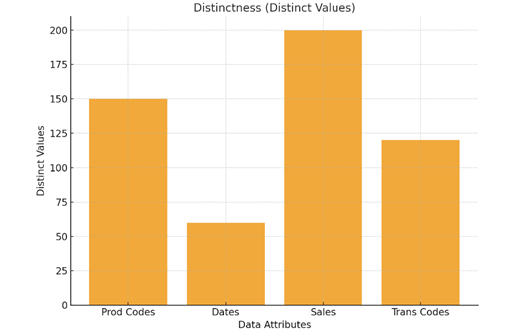
Figure 4. Distinctness. This chart visualizes the distinctness of data in various columns, which refers to the number of unique values present in each attribute.
Contact
- Prof. Kamelia Stefanova, [email protected],
- Prof. Valentin Kisimov, [email protected],
- Assist. Dr. Ivona Velkova, [email protected]
University of National and World Economy, Bulgaria