Scientific/governmental/private partners involved
TBI Bank is driven by the goal to build the leading challenger bank in Southeastern Europe. As a diverse team of 19 nationalities and expertise from all around the globe, they can make their customers’ lives easier. They embrace constant learning and put clients at the heart of everything they do. This places TBI as one the most efficient and profitable banks in SEE. Their core markets are Bulgaria, Romania and Greece as we also have activities in Germany and Lithuania, serving a customer base of over 2.2 million individuals across these regions.
Technical/scientific Challenge
Effectively integrating multiple high-performance Generative AI systems (such as Large Language Models) into business workflows presents multiple key technical and scientific challenges.
Most state-of-the-art LLMs are built on autoregressive frameworks, meaning they generate text sequentially, predicting each token based solely on preceding tokens. Models have a finite context window, which restricts the amount of background information and detail that can be incorporated into prompts and responses. Generating lengthy or highly detailed responses often leads to issues with maintaining consistent logic, style, and accuracy across the entire output.
Currently, there is no standardized, streamlined workflow to manage the lifecycle of generative AI interactions effectively. Manually consolidating outputs from multiple LLMs requires human judgment or additional software tools, adding complexity and inefficiency to workflows.
Ensuring the final output meets high standards for quality, accuracy, readability, and originality poses additional scientific and technical problems. Combining multiple outputs intelligently requires advanced natural language processing techniques and specialized tools.
Adjusting the final merged text for consistent tone, style, and grammatical correctness is critical for professionalism but introduces additional layers of complexity. Reliably detecting and mitigating potential plagiarism or originality issues is essential yet challenging, particularly when balancing automated processes and manual oversight.
Solution
To ensure the highest quality and consistency in the final results provided to the end user, the outputs from the selected Large Language Models (OpenAI’s GPT-4o, Anthropic’s Claude 3.5 Sonnet, and Google’s Gemini 1.5) undergo a structured merging and refinement process. The merging procedure involves pairwise combinations of responses leveraging external tools such as EasyPeasy.ai and the OpenAI o1 API [1] (the current state-of-the-art reasoning model).
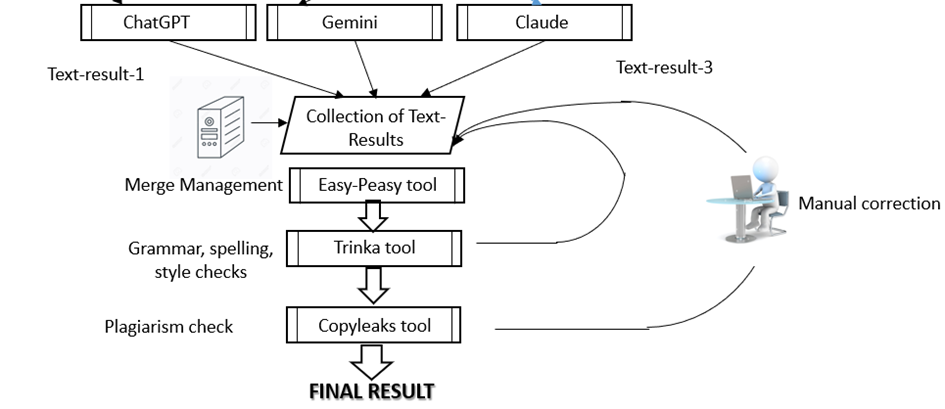
Figure 1: Architecture of the second stage (after the prompt has been distributed among different models and we’ve received their outputs)
Pairwise Merging
Outputs from two models are merged using EasyPeasy.ai’s text-merging capability[2]. This tool intelligently consolidates distinct strengths, clarity, and coherence into one unified text, ensuring comprehensive coverage of key points and reducing redundancy.
The merging is performed in pairs of two – the first two outputs – Text_Output_1 and Text_Output_2 are merged into Result_1 and then Result_1 is merged with Text_Output_3 to get to the final merged result.
An alternative approach is using a reasoning model (like OpenAI’s o1 or DeepSeek R1) to perform the merging, since these models can use their “thinking” to reason about the similarities and differences among the three different outputs.
Quality Assurance of the Merged Output
Once the merged output is finalized into a single coherent piece, the text undergoes additional rigorous quality assurance steps.
Spelling, Grammar, Style, and Tone Check (Trinka Grammar Checker API[3])
The integrated text is validated for language accuracy, grammatical correctness, consistency in style, and appropriateness of tone using the robust capabilities of the Trinka Grammar Checker API.
Any identified linguistic issues—such as typographical errors, stylistic inconsistencies, awkward phrases, or inappropriate tone—are automatically corrected, ensuring professional-quality language suitable for the specified target audience.
Plagiarism Check (Copyleaks API[4])
After ensuring linguistic quality, the output undergoes an originality assessment via Copyleaks API to verify that the merged text maintains high originality standards.
Copyleaks returns a plagiarism confidence score. A threshold of at least 80% originality is required to pass. Outputs below this threshold are flagged and either reprocessed or reviewed manually, maintaining content authenticity and integrity.
Final Adjustments and Enhancements
Once the text passes both linguistic quality and originality checks, it undergoes one final round of enhancements using the OpenAI o1 API. The objective of this stage is to incorporate subtle refinements based on the outcomes of previous validation steps:
- Style refinement: Ensure a smooth narrative flow.
- Clarification improvements: Eliminate ambiguous or unclear wording.
- Precision enhancements: Reinforce exactness and factual reliability.
- Tone adjustments: Ensure alignment with the specified nuance and intent.
Upon completion of the comprehensive quality assurance and refinement phases, the system presents the final output through an intuitive and user-friendly web interface.
Users are provided with options to either approve the final result or submit feedback for additional fine-tuning and reprocessing
Scientific impact:
- Proposes a new method (as a part of the whole system) for systematically merging diverse LLM outputs to leverage complementary model strengths.
- Establishes robust post-processing validation protocols in order to enhance output reliability and user trust.
- Provides empirical data on the efficacy of AI-driven text merging and enhancement technique.
Benefits
- Provides users with singular, authoritative outputs that represent the collective intelligence of multiple generative AI models.
- Removes manual overhead for users, delivering a polished, publication-quality result ready for immediate use.
Success story # Highlights
- An iterative workflow for merging and quality assurance of large language models outputs is presented and implemented.
- User-friendly web interface for reviewing and managing the process step-by-step.
Contact
- Venko Andonov, University of National and World Economy, Sofia
- Valentin Kisimov, University of National and World Economy, Sofia
[1] https://openai.com/o1/
[2] https://easy-peasy.ai
[3] https://trinka.ai
[4] https://copyleaks.ai